What Is Reverse ETL? Essential Guide 2026

Reverse ETL is the process of sending clean, enriched data from a central data warehouse back into the operational tools business teams use every day, like CRMs, ad platforms, email software, and support systems. In some operational tools, especially email and support platforms, “real-time” can still mean 15 to 45 minutes of delay because of API throttling and batch processing, which is exactly why marketers need to understand how Reverse ETL works before they depend on it for triggers.
You probably already have the ingredients for better targeting. Product usage data sits in Snowflake or BigQuery. Lead scores live in a model your data team trusts. Support activity is available somewhere. But your campaign builder, CRM, and chat platform still run on thinner, older, or disconnected customer data.
That gap is where good strategy goes to die. Marketing knows who should get the onboarding sequence, who should be suppressed from upsell messaging, and who is showing buying intent. The problem is that those insights often stay trapped in the warehouse, inside dashboards, or in analyst notebooks instead of reaching the tools where campaigns are run.
The easiest way to think about Reverse ETL is this. Your data warehouse is a central city library. It stores the full catalog, organized and trustworthy. Reverse ETL is the librarian who takes the right curated books, meaning the insights you need, and delivers them directly to people's desks, meaning Salesforce, HubSpot, ad platforms, Intercom, Zendesk, and email tools. Teams don't have to walk back to the library every time they need context. The right information shows up where they already work.
The Data Dilemma Modern Marketers Face
Most marketing teams don't have a data collection problem. They have an activation problem.
They track website behavior, product events, demo requests, support conversations, billing status, and lifecycle stage. Then they load all of that into a warehouse because that's the right place to clean it up, model it, and create a single source of truth. But once it's there, a familiar bottleneck appears. The warehouse becomes great for analysis and weak for action.
A marketer wants to target product-qualified leads in Salesforce. A lifecycle manager wants to suppress users with an open support issue from a promotional send. A growth team wants to personalize messaging based on feature adoption. None of those are difficult ideas. What's difficult is getting the right modeled data into the tools quickly, consistently, and without another CSV export.
Where the friction shows up
Here's what this usually looks like in practice:
- Manual exports: Someone pulls a list from the warehouse, cleans it in a spreadsheet, and uploads it into a marketing tool.
- Stale segmentation: CRM fields don't reflect the latest product or support data, so campaigns use old logic.
- Engineering dependency: Every operational request becomes a ticket, even when the business question is straightforward.
- Channel mismatch: Analytics live in one place, but execution lives somewhere else.
Practical rule: If a high-value audience only exists in a dashboard, it isn't operational yet.
This is why the question “what is Reverse ETL” matters to marketers, not just to data teams. Reverse ETL closes the gap between insight and execution by syncing clean, modeled warehouse data back into the business systems where teams take action. According to ClicData's explanation of Reverse ETL, it reverses the traditional ETL flow by moving processed insights from the warehouse into operational applications so teams can make decisions inside their normal workflows.
That changes the warehouse from passive storage into a working growth asset.
ETL vs Reverse ETL Understanding the Data Flow
Traditional ETL and Reverse ETL use similar pipeline mechanics, but they solve different business problems. ETL brings data into the warehouse so teams can analyze it. Reverse ETL takes the cleaned, modeled result and sends it back into the systems that run campaigns, sales motions, and support workflows.
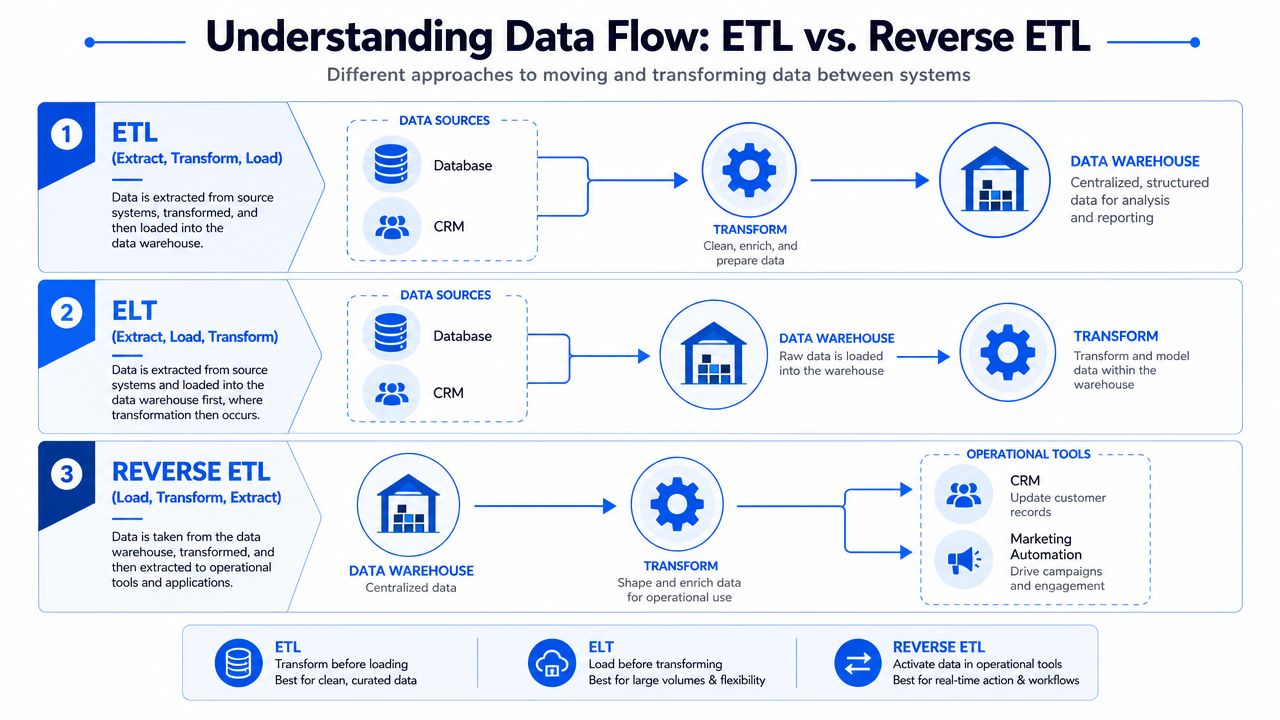
The simple directional difference
ETL and ELT move data toward the warehouse. Reverse ETL moves selected outputs away from it.
That directional change sounds small on paper. In practice, it changes who can use the data and how quickly they can act on it. A warehouse can hold the right churn score, product usage segment, or lifecycle flag for days without affecting revenue. The moment that same field lands in HubSpot, Braze, Intercom, or Salesforce, a marketer can suppress a risky send, trigger a nurture path, or route a high-intent account to sales.
Using the library analogy from earlier, ETL stocks the central city library with books from across the organization. Reverse ETL is the librarian delivering the right curated books directly to each person's desk, inside the tools they already use. That delivery step is what turns stored knowledge into action.
A side-by-side comparison
| Process | Data starts in | Data ends in | Main goal |
|---|---|---|---|
| ETL | Business systems and apps | Data warehouse | Consolidate data for analysis |
| ELT | Business systems and apps | Data warehouse, then transformed there | Centralize first, model later |
| Reverse ETL | Data warehouse | CRMs, ad tools, email tools, support systems | Activate modeled data in workflows |
The distinction matters even more in operational channels that run on short windows. A weekly dashboard can tolerate delay. An email platform deciding who should get today's product announcement cannot. A support chat tool deciding whether a customer is high value or at risk also needs current context, not last week's export. That latency problem is one of the biggest gaps in high-level explanations of Reverse ETL.
The other gap is implementation. Reverse ETL is not just a sync category inside a broader guide to marketing data integrations. It forces teams to choose refresh frequency, identity resolution rules, field mapping, failure handling, and destination limits. Marketers feel those trade-offs directly. Faster syncs improve relevance, but they also increase API pressure, raise the odds of conflicting updates, and expose weak source logic faster.
Why marketers should care about the difference
Marketing teams often benefit from ETL indirectly. The warehouse gives them cleaner reporting, better attribution, and more reliable definitions. But growth happens in execution systems, not in BI tabs.
For that reason, Reverse ETL often matters more to growth than another dashboard does. It puts trusted warehouse logic into the places where segmentation, suppression, lead routing, personalization, and service prioritization happen.
If your team also works with revenue planning, billing, or account health data, it helps to understand broader techniques for integrating financial data. The tooling differs, but the operating principle is the same. Data only creates business value once the destination system can use it correctly and on time.
ETL helps teams understand customer behavior. Reverse ETL helps marketers and operators act on it while the moment still matters.
How Reverse ETL Architecture Actually Works
Under the hood, Reverse ETL is less mysterious than it sounds. It's a repeatable pipeline with a warehouse on one end and operational tools on the other.
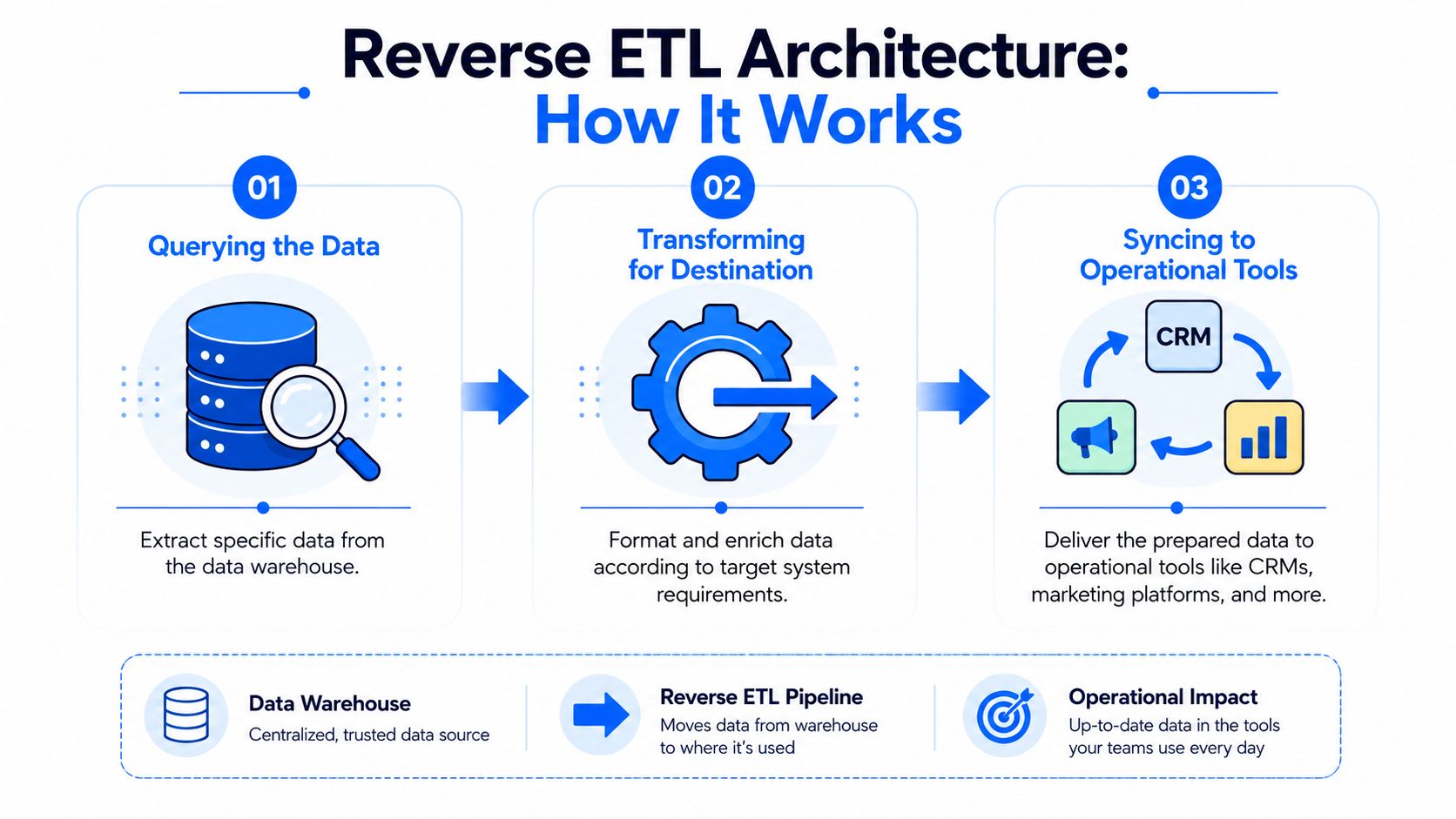
Step one pulls the right records
The process starts in the warehouse. Teams query modeled data that's ready for use, not raw event logs.
That might be:
- product-qualified leads
- customer health scores
- feature adoption flags
- lifecycle stage
- LTV predictions
- open-ticket suppression lists
Reverse ETL performs optimally when the warehouse already contains business-ready logic. If your source model is messy, the sync just moves messy data faster.
Step two maps warehouse fields to destination fields
After the right records are selected, the data has to fit the destination system. Salesforce may expect one field name. HubSpot may require another. An email platform may only accept certain formats for traits, timestamps, or status values.
Teams usually uncover the extensive work involved. Reverse ETL isn't just “send table A to tool B.” It's also deciding which warehouse field maps to which application field, what to do with null values, how to handle status changes, and whether the destination should overwrite or append.
A useful companion read here is this glossary entry on integrations, because many implementation problems are really integration problems disguised as data problems.
Later in the pipeline, the system pushes records through APIs or native connectors.
Step three syncs only what changed
Well-built Reverse ETL systems don't resend the entire dataset every time. In Integrate.io's write-up on Reverse ETL architecture, the warehouse is treated as the source and operational tools as the target, while a single batch job computes delta changes from snapshot tables. A sink layer then batches records and calls destination APIs to insert or update them. That same architecture can classify sync failures and automatically re-ingest failed records in later runs, which is one of the reasons these tools are more reliable than manual exports.
What works and what doesn't
A few implementation patterns are consistently effective:
- Use modeled tables, not raw events: Destination tools need curated attributes, not event noise.
- Keep ownership clear: Data teams should define trusted models. Marketing and ops teams should define activation logic.
- Start with a small field set: Shipping ten useful traits beats shipping fifty weakly defined ones.
What usually fails:
- Syncing before the data model is settled: You'll spend your time fixing mappings instead of learning.
- Treating every destination the same: Salesforce, Zendesk, and email tools all have different constraints.
- Ignoring failure handling: If failed records don't retry cleanly, trust in the whole setup drops fast.
Why Reverse ETL Is a Game Changer for Marketers
Reverse ETL matters because it changes the speed and quality of marketing decisions. Not by generating new insight on its own, but by making existing insight usable inside daily execution tools.
Organizations generally understand what better targeting looks like. They want campaigns shaped by product activity, account status, support context, and buying signals. The blocker isn't imagination. The blocker is getting trusted data into the systems where those decisions become audiences, journeys, exclusions, and alerts.
It turns warehouse logic into channel action
The biggest shift is operational. Instead of asking analysts for one-off lists, marketers can work from warehouse-defined audiences and traits that sync into their platforms on a schedule.
That means you can:
- Build sharper audiences: Push product-qualified leads into a CRM or ad audience instead of relying on form fills alone.
- Improve suppression logic: Keep customers with active issues out of aggressive expansion messaging.
- Personalize with confidence: Use standardized industry, plan, lifecycle, or usage data across channels.
- Reduce field drift: Keep customer attributes aligned between the warehouse and frontline tools.
This is one reason Reverse ETL is often discussed as part of a composable CDP model. In Improvado's introduction to Reverse ETL, it's framed as a way to create a composable CDP foundation where audiences and traits can be activated across channels while governance remains anchored in the warehouse. That combination matters. Marketers get self-serve activation, while data teams keep quality, security, and compliance under control.
It improves marketing workflows, not just marketing reports
A dashboard can tell you which users are drifting toward churn. Reverse ETL can put that signal where your team can act on it.
That operational layer improves work in ways dashboards alone can't:
| Marketing need | Without Reverse ETL | With Reverse ETL |
|---|---|---|
| Audience building | Manual list pulls | Synced warehouse segments |
| Personalization | Limited tool-native fields | Richer customer traits |
| Sales alignment | CRM fields go stale | Shared modeled attributes |
| Lifecycle campaigns | Static rules | Data-driven triggers and suppressions |
The value isn't in moving data for its own sake. The value is in reducing the distance between a trustworthy signal and a customer-facing action.
It gets more ROI from the stack you already have
A lot of martech spending goes underused because the systems don't share context. The email platform can send. The CRM can route leads. The support tool can display customer records. But none of them are as useful as they should be when they only know what happened inside their own walls.
Reverse ETL lets you use warehouse intelligence to make those tools smarter.
That's especially relevant if you're tightening CRM processes or cleaning up revenue handoffs. If that's your focus, these CRM best practices for growth teams pair well with Reverse ETL because clean activation depends on clean destination logic too.
The practical takeaway is simple. Reverse ETL doesn't replace strategy, segmentation, or messaging. It makes those disciplines executable at the level your warehouse data already deserves.
Reverse ETL Use Cases for B2B Newsletters and Growth
For newsletter and lifecycle teams, Reverse ETL gets interesting when it stops being abstract and starts shaping sends, suppressions, and targeting logic.
Segment by behavior, not just form data
A standard B2B email setup usually knows title, company, source, and maybe lifecycle stage. That's useful, but it's thin.
A warehouse often knows far more. It can identify who activated a key feature, who invited teammates, who hasn't logged in recently, or who engaged with pricing content after a product trial. Reverse ETL syncs those modeled traits into the email tool so the newsletter team can build segments around actual behavior instead of broad assumptions.
For example:
- Power users can receive product education, referral prompts, or expansion-oriented content.
- At-risk users can move into a reactivation sequence with training and support resources.
- Newly activated accounts can get a shorter, action-focused onboarding track.
Personalize content with richer attributes
Personalization doesn't have to mean dropping a first name into a subject line. For B2B growth, the better play is usually contextual relevance.
When Reverse ETL sends enriched traits into an email platform, campaigns can adapt to things like industry, account type, product maturity, or lead classification. A SaaS consultant, an enterprise RevOps lead, and a startup founder might all get the same newsletter issue with different CTAs or content modules because the warehouse provides the context.
That's where data enrichment in marketing systems becomes closely related. Enrichment gives you the inputs. Reverse ETL makes sure those inputs show up in the tools that need them.
Better newsletter targeting usually doesn't start in the email platform. It starts upstream in the warehouse model.
Trigger campaigns from product-qualified signals
This is a common growth motion. A user crosses some threshold in product behavior that suggests real buying intent or readiness for expansion. The data team models that threshold in the warehouse. Reverse ETL sends the resulting flag or audience into the destination platform.
From there, the marketing team can:
- Launch onboarding journeys for newly qualified users
- Notify sales when an account reaches a meaningful usage milestone
- Queue nurture paths for leads that match an ICP and show activation signals
- Pause generic campaigns when the user enters a more relevant lifecycle track
The operational win is consistency. Everyone acts on the same definition of “qualified” because the source logic lives in the warehouse.
Protect customer experience with smart suppression
This is one of the least flashy and most valuable use cases.
Say a customer has a recent support escalation or an unresolved issue in Zendesk or Intercom. Without Reverse ETL, that context may never reach the email platform in time. The result is a polished promotional campaign landing in the inbox of someone who's frustrated and waiting for help.
With Reverse ETL, a modeled suppression field can move into your campaign tool and block that send automatically.
That doesn't just protect brand experience. It helps teams avoid the internal friction that comes from support asking why marketing sent the wrong message to the wrong account.
Your Guide to Adopting Reverse ETL
Teams usually go wrong with Reverse ETL in one of two ways. They either start too big, or they assume the hardest part is the connector. In practice, the first win comes from choosing one business problem with clear downstream action, then validating whether the destination can absorb the data the way you expect.

Start with one high-value use case
Don't begin with “sync everything to every tool.” Start with a case where the business logic is already understood and the operational action is obvious.
Good first candidates usually look like this:
- PQL activation: sync product-qualified lead flags into CRM and lifecycle tools
- Suppression logic: keep active support cases out of promo campaigns
- Lifecycle routing: update sales or customer success tools when account stage changes
- Audience refresh: maintain current segments in ad or email platforms
A strong first use case has three traits. The source data is trusted. The destination team is ready to act on it. The value of being more current is easy to understand.
Evaluate tooling with practical questions
Tool selection matters, but it shouldn't be reduced to a features checklist. The right question is whether the platform fits your architecture, your team structure, and the systems you need to update.
Ask vendors or internal builders:
| Question | Why it matters |
|---|---|
| Can it sync from our warehouse model directly? | You want warehouse-first activation, not another data copy. |
| How does it handle schema changes? | Destination mappings break when fields change. |
| What happens on failed syncs? | Reliability matters more than a polished demo. |
| Can business teams see sync status? | Activation falls apart when only engineering has visibility. |
| How are permissions and governance handled? | Sensitive traits shouldn't spread loosely across tools. |
If the end goal includes better campaign conversion after the click, it also helps to pair activation planning with conversion work. This guide to improving landing page performance is useful because sharper audience targeting only pays off if the destination experience is equally tight.
Define the destination behavior before the sync
A common mistake is obsessing over what data to send before deciding how the receiving system should use it.
For each field or audience, answer:
- Who owns it in the destination?
- What workflow depends on it?
- Should it overwrite an existing field or populate a new one?
- What should happen if the value disappears or changes state?
Those decisions are often more important than the connector itself. A clean warehouse trait can still create a mess if it maps into the wrong CRM field or triggers the wrong automation.
One caution: Reverse ETL is not a substitute for data modeling discipline. If your definitions are unstable, the sync will just distribute confusion faster.
Watch the real-time latency gap
This is the implementation issue most broad explainers gloss over.
In Striim's discussion of Reverse ETL and operational teams, a key pitfall is the real-time latency gap. Operational systems like email platforms and support tools can have 15 to 45 minute latency windows because of API throttling and batch processing. That means a trigger that feels instantaneous in a CRM workflow may be too slow for a campaign that depends on immediate action.
For marketers, the lesson is simple:
- Use Reverse ETL for synchronized activation, not for every sub-minute interaction.
- Check destination constraints early, especially with email and support platforms.
- Separate “fresh enough” from “instant” before promising real-time personalization.
If you need immediate in-app messaging or event-driven product responses, Reverse ETL may be part of the picture, but not the whole stack.
Monitor the pipeline like a revenue system
Once live, Reverse ETL needs operational oversight.
Track:
- Field-level accuracy: does the destination contain the value you expect?
- Audience logic: do synced lists match warehouse definitions?
- Failure recovery: are rejected or delayed records retried correctly?
- Workflow impact: are sales, support, and campaign automations behaving as intended?
The teams that get value from Reverse ETL treat it as part of go-to-market infrastructure, not as a side integration. They review mappings, retire unused traits, and keep destination logic aligned with source-of-truth models.
Breaker helps B2B marketers turn better data into better newsletter growth. If you want a platform that combines sending, targeting, list expansion, analytics, and deliverability support in one place, take a look at Breaker.












